Anomaly Detection
Anomaly detection identifies abnormal system behavior in real-time operations and infrastructure. It helps energy teams detect faults, cyber-physical risks, asset degradation and operational deviations before they escalate into outages or safety incidents.
What It Is
Anomaly detection compares live operational data against expected behavior. In energy systems, this can include unusual grid frequency movements, pressure deviations, abnormal equipment temperatures, unexpected power flows, suspicious access events or telemetry patterns that do not match normal operation.
The goal is not simply to generate alerts. The goal is to identify meaningful deviations early enough for operators to investigate, prioritize and respond.
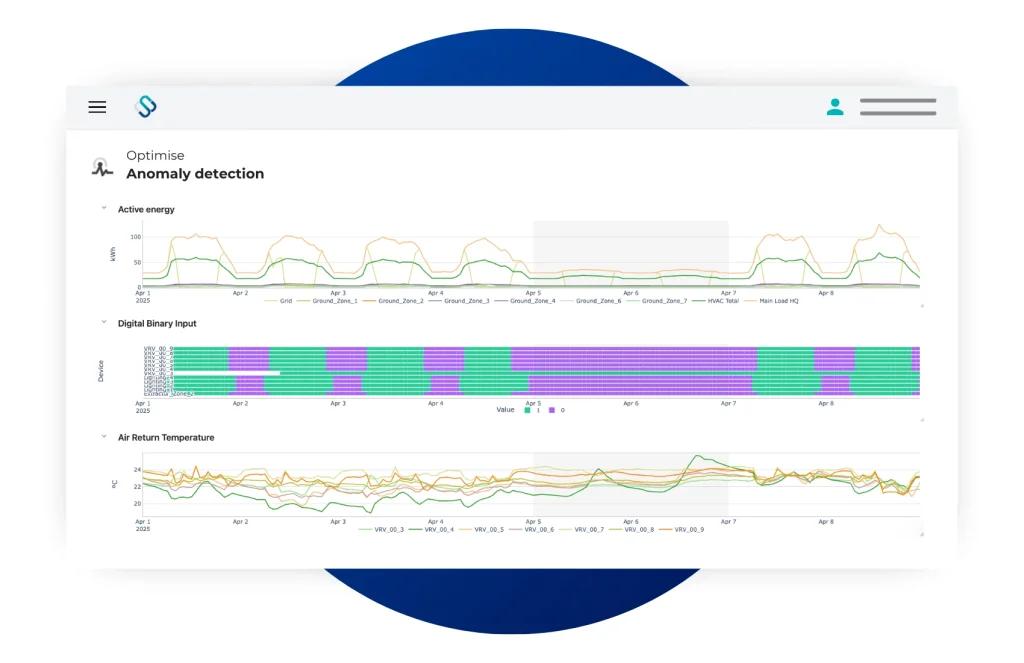
Key Pain Points
Modern energy infrastructure generates high-volume telemetry across assets, control systems and distributed sites. Important signals can be difficult to detect manually.
Signal Types
Anomaly detection can operate on many types of energy data. The signal type determines which models and response workflows are appropriate.
| Signal Type | Example Anomaly | Operational Meaning |
|---|---|---|
| Grid telemetry | Unexpected voltage, frequency or power-flow deviation | Possible instability, congestion or equipment issue |
| Asset sensors | Temperature, vibration or pressure outside normal patterns | Possible degradation, leak, overheating or mechanical fault |
| SCADA events | Unexpected command sequence or control-state change | Possible operator error, automation issue or cyber-physical risk |
| Market and demand data | Unusual load spike, price movement or dispatch behavior | Possible demand event, data issue or market disruption |
Detection Workflow
Effective anomaly detection connects data monitoring to investigation and response, rather than stopping at alert generation.
Methods
Anomaly detection often combines simple rules with statistical models and machine learning. The best approach depends on data volume, labels, explainability needs and operating context.
Operational Response
An anomaly is only useful if it leads to the right response. Response logic should separate noise from meaningful events and connect alerts to investigation workflows.
| Response Area | What Happens |
|---|---|
| Operator alerting | High-confidence anomalies are surfaced with context, severity and recommended next steps. |
| Maintenance planning | Asset-related anomalies can trigger inspection or work order creation. |
| Cyber-physical security | Unusual command, access or control patterns can be escalated to security teams. |
| Grid operations | Grid anomalies can support redispatch, switching, reserve activation or further simulation. |
Key Performance Metrics
Anomaly detection should be measured by alert quality, response usefulness and operational impact.
Limitations & Practical Considerations
Anomaly detection can fail when models do not understand operating context. A pattern that is abnormal during normal operation may be expected during maintenance, storms or emergency response.
Systems should include feedback from operators, clear severity levels, explainable context and regular tuning to avoid alert fatigue.
Related Deep Dives
Anomaly detection connects AI intelligence with real-time analytics, predictive maintenance, infrastructure monitoring and energy security.